AI + Web3: タワーとスクエア
この記事では、Web3がAIテクノロジースタックで提供する機会に焦点を当てており、計算能力の共有、データプライバシーの保護、モデルのトレーニングと推論を含むAIがファイナンス、インフラ、およびWeb3の新しい物語をどのように支えるかを探っています。分散型計算能力ネットワークからAIエージェントの冷たいスタート、オンチェーン取引のセキュリティから生成的NFTまで、AIとWeb3の統合が革新と機会に満ちた新しい時代を切り拓いています。要するに、
- AI concept Web3プロジェクトは、一次市場と二次市場で魅力的な投資ターゲットとなっています。
- AI業界におけるWeb3の機会は、分散型インセンティブを使用して潜在的な供給を長い尾部に調整することにあります - データ、ストレージ、および計算の分野を横断して。同時に、AIエージェントのためのオープンソースモデルと分散型マーケットを確立することが重要です。
- AIは、主にオンチェーンファイナンス(暗号通貨の支払い、取引、データ分析)や開発支援など、Web3業界で重要な役割を果たしています。
- AI+Web3の有用性は、両者の補完関係にあります:Web3はAIの中央集権化に対抗することが期待されており、AIはWeb3が閉じ込められることなく自由になるのを助けることが期待されています。
導入
過去2年間、AIの開発は加速されてきました。Chatgptによって引き起こされたバタフライエフェクトのように、生成的人工知能の新しい世界を切り拓くだけでなく、遠いWeb3でトレンドを巻き起こしています。
AIコンセプトの恩恵を受けて、仮想通貨市場の資金調達は停滞に比べて大幅に増加しました。メディアの統計によると、2024年上半期のみで、合計64のWeb3+AIプロジェクトが資金調達を完了し、AIベースのオペレーティングシステムZyber365がシリーズAラウンドで1億ドルの最高額の資金調達を達成しました。
二次市場はより繁栄しており、暗号化集約ウェブサイトCoingeckoのデータによると、わずか1年余りでAIトラックの総市場価値は4850億ドルに達し、24時間の取引高は約860億ドルに達しています。主流のAI技術進展によってもたらされる明白な利益は、OpenAIのSoraテキスト・ビデオモデルがリリースされた後、AI部門の平均価格が151%上昇しました。AI効果は、暗号通貨の一つであるMemeというゴールド吸収セクターにも放射され、初のAIエージェントコンセプトMemeCoin - GOATは急速に人気を博し、140億ドルの評価額を達成し、成功裏にAI Memeブームを引き起こしました。
AI+Web3に関する研究やトピックは同様に熱いです。AI+DepinからAI Memecoin、そして現在のAIエージェントやAI DAOまで、FOMO感情は既に新しいナラティブのスピードに遅れています。
AI+Web3、この用語の組み合わせは、ホットマネー、トレンド、未来の幻想に満ちており、資本によって仕組まれた結婚と見なされています。この華やかなローブの下には、投機家たちの本拠地なのか、夜明け前の前夜なのかを区別するのは難しいようです。
この質問に答えるために、両者にとって重要な考慮事項は、お互いがより良くなるかどうかですか? お互いのパターンから利益を得ることができますか? この記事では、先人の肩に立つという観点からこの状況を考察しようともしています: Web3がAIテクノロジースタックのさまざまな側面でどのような役割を果たすことができ、AIがWeb3にもたらす新しい活力は何でしょうか?
Web3がAIスタックの下で持つ機会は何ですか?
このトピックに入る前に、AI大規模モデルの技術スタックを理解する必要があります:
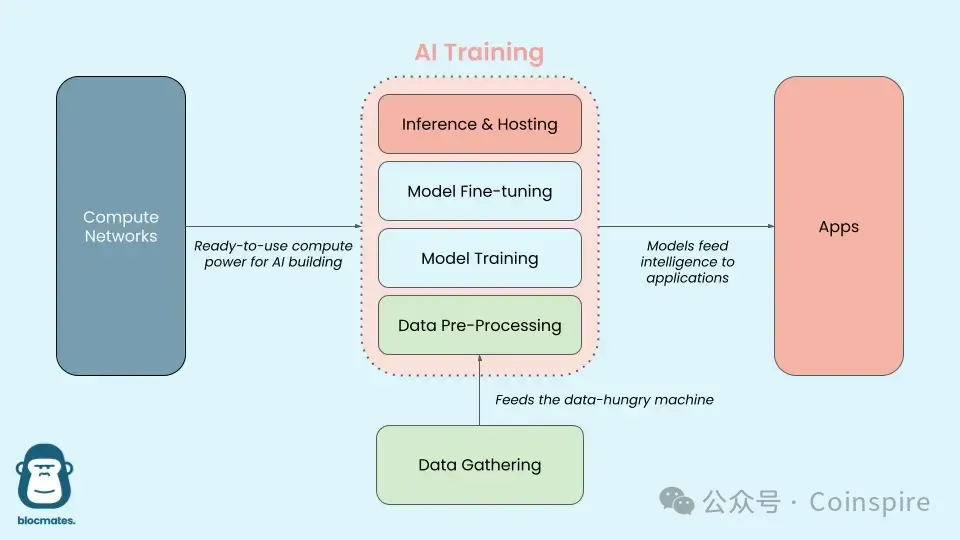
Image Source: Delphi Digital
より簡単な言葉で言えば、「大きなモデル」とは人間の脳のようなものです。早い段階では、この脳は世界に生まれたばかりの赤ちゃんのようであり、世界を理解するために広範囲な外部情報を観察し吸収する必要があります。これがデータの「収集」段階です。コンピュータは人間のように複数の感覚を持っていないため、トレーニング前に大規模な非注釈の外部情報をコンピュータが理解して使用できる形式に変換するために「前処理」する必要があります。
データを入力した後、AIは「トレーニング」として理解や予測する能力を持つモデルを構築します。これは、徐々に外部の世界を理解し学習する赤ちゃんの過程と見なすことができます。モデルのパラメータは、学習プロセス中に赤ちゃんが継続的に調整する言語能力のようです。学習コンテンツが特化し始めたり、人々とのやり取りからフィードバックを受けて修正を行うと、大規模なモデルの「微調整」段階に入ります。
子どもが成長し話すことを学ぶにつれて、新しい会話で意味を理解し感情や思いを表現できるようになるのは、AI大規模モデルの「推論」と似ています。モデルは新しい言語やテキスト入力を予測し分析できます。赤ちゃんは言語能力を通じて感情を表現し、物を説明し、さまざまな問題を解決しますが、これは訓練を完了した後の推論段階でのAI大規模モデルのさまざまな特定のタスクへの応用とも似ています。例えば、画像分類、音声認識などです。
AIエージェントは、大きなモデルの次の形に近づいています。独自にタスクを実行し、複雑な目標を追求する能力を持つだけでなく、思考能力を持ち、記憶し、計画し、ツールを使って世界とやり取りすることができます。
現在、さまざまなスタックでAIの課題に取り組んでいる中で、Web3は初期段階で多層化された相互接続されたエコシステムを形成し、AIモデルプロセスのさまざまな段階をカバーしています。
最初、ベースレイヤー:コンピューティングパワーやデータのAirbnb
計算能力
現在、AIの最も高いコストの1つは、モデルのトレーニングと推論モデルに必要な計算能力とエネルギーです。
MetaのLLAMA3の1つの例は、NVIDIAが生産した16,000台のH100GPU(人工知能と高性能コンピューティングワークロードに特化したトップのグラフィックス処理ユニット)を使用して、30日間でトレーニングを完了する必要があります。後者の80GBバージョンの価格は30,000ドルから40,000ドルの間で、ハードウェア投資額は40-70億ドル(GPU +ネットワークチップ)が必要です。さらに、月次のトレーニングには160億キロワット時が必要で、月間のエネルギー消費量はほぼ2,000万ドルです。
AIコンピューティングパワーの解凍に関して、これはWeb3がAIと交差する最も早い分野でもあります - DePin(分散物理インフラネットワーク)。現在、DePin Ninjaデータウェブサイトには、io.net、Aethir、Akash、Render NetworkなどのGPUコンピューティングパワー共有代表プロジェクトを含む1400以上のプロジェクトが表示されています。
主なロジックは次のとおりです: プラットフォームは、許可なく分散型で個人やエンティティがアイドルGPUリソースを提供し、UberやAirbnbのようなオンラインマーケットプレイスを介して未使用GPUリソースの利用を増やし、購入者と販売者のためにより多くのコスト効率の良い計算リソースを提供することで、エンドユーザーがより効率的な計算リソースを得ることができるようにしています。同時に、ステーキングメカニズムも、品質管理メカニズムやネットワークの中断に対する違反があれば、リソースプロバイダーが対応するペナルティに直面することを保証しています。
その特徴は:
- GPUリソースのプール化: 供給業者は主に第三者の独立した中小データセンターや、暗号化マイニングなどのオペレーターからの余剰な計算リソース、FileCoinやETHマイナーなどのPoSコンセンサスメカニズムを持つマイニングハードウェアです。現在、MacBook、iPhone、iPadなどのローカルデバイスを利用して、大規模なモデル推論を実行するための計算リソースネットワークを構築するためのエントリーバリアの低いデバイスを提供するプロジェクトもあります。
- AIコンピューティングパワーの長尾市場に直面する:a.「技術的には」、分散コンピューティングパワー市場は推論段階により適しています。トレーニングは、超大規模クラスタスケールGPUによってもたらされるデータ処理能力に依存しており、推論は比較的GPUコンピューティング性能が低く、例えば低遅延のレンダリング作業とAI推論アプリケーションに焦点を当てたAethirなどが該当します。b.「需要の観点から」、中小規模のコンピューティングパワー需要者は個々に大規模なモデルをトレーニングするのではなく、わずかなヘッドモデルを中心に最適化および微調整するだけであり、これらのシナリオは自然に分散アイドルコンピューティングパワーリソースに適しています。
- 分散化された所有権:ブロックチェーンの技術的な重要性は、リソース所有者が常に自分のリソースをコントロールし続け、需要に応じて柔軟に調整し、同時に利益を得ることができることにあります。
データ
データはAIの基盤です。データがないと、計算は無意味であり、データとモデルの関係は「入れたものは出る」のことわざのようです。データの量と質が最終モデルの出力品質を決定します。現在のAIモデルのトレーニングでは、データがモデルの言語能力、理解能力、さらには価値観や人間らしいパフォーマンスまで決定します。現在、AIのデータ需要のジレンマは主に以下の4つの側面に焦点を当てています。
- データハンガー:AIモデルのトレーニングは大量のデータ入力に大きく依存しています。 公開情報によると、OpenAIによるGPT-4のトレーニング用パラメーター数は1兆レベルに達しています。
- データ品質:AIと様々な産業の組み合わせにより、業界固有のデータのタイムリネス、多様性、専門性、およびソーシャルメディアのセンチメントなどの新興データソースの取り込みに対する新たな要件が提案されています。
- プライバシーとコンプライアンスの問題:現在、さまざまな国や企業が高品質なデータセットの重要性について徐々に認識し、データクローリングに制限を課しています。
- 高いデータ処理コスト:大量のデータ、複雑な処理。公開情報によると、AI企業の研究開発費の30%以上が基本的なデータ収集と処理に使用されていることが示されています。
現在、web3のソリューションは次の4つの側面に反映されています:
1. データ収集:スクレイピング用に自由に利用できる現実世界のデータは急速に枯渇しており、AI企業のデータに対する費用は年々増加しています。しかし、同時に、この支出はデータの実際の貢献者に還元されていません。プラットフォームはデータによってもたらされる価値創造を完全に享受しており、例えばRedditはAI企業とのデータライセンス契約によって総額2億3,000万ドルの収益を生み出しています。
Web3のビジョンは、データによってもたらされる価値創造に参加することができる真に貢献するユーザーが、分散ネットワークとインセンティブメカニズムを通じて、より個人的で貴重なデータを効果的な方法で取得することを可能にすることです。
- As Grassは分散型データレイヤーおよびネットワークであり、ユーザーはGrassノードを実行し、アイドル帯域幅を提供し、トラフィックを中継することで、インターネット全体からリアルタイムデータを取得し、トークン報酬を受け取ることができます;
- Vanaは、ユーザーがプライベートデータ(購買記録、ブラウジング習慣、ソーシャルメディアの活動など)を特定のDLPにアップロードし、このデータを特定の第三者に使用するために許可するかどうかを選択できるData Liquidity Pool(DLP)という独自のコンセプトを紹介しています。
- PublicAIでは、ユーザーは#AIまたは#Web3をXの分類タグとして使用できます@PublicAIデータ収集は達成できます。
2. データの前処理:AIのデータ処理では、収集されたデータが通常ノイズが多くエラーを含んでいるため、モデルをトレーニングする前に、標準化、フィルタリング、欠損値の処理などの繰り返しタスクを行い、使用可能な形式に変換する必要があります。この段階は、AI業界における数少ない手作業プロセスの1つであり、データ注釈者の産業を生み出しています。モデルがデータ品質に対する要件を高めるにつれて、データ注釈者の閾値も上昇しています。このタスクは、Web3の分散型インセンティブメカニズムに自然に適しています。
- 現在、GrassとOpenLayerはともにデータ注釈を追加することを重要なステップとして検討しています。
- Synesisは、ユーザーが注釈付きデータ、コメント、またはその他の形式の入力を提供することで報酬を得ることができる、データ品質を重視した「Train2earn」のコンセプトを提案しました。
- データラベリングプロジェクトSapienは、ラベリングタスクをゲーム化し、ユーザーがポイントをステークしてさらにポイントを稼ぐことを可能にします。
3. データプライバシーとセキュリティ: データプライバシーとセキュリティは2つの異なる概念であることを明確にする必要があります。データプライバシーは機密データの取り扱いを、データセキュリティはデータ情報を未承認のアクセス、破壊、盗難から保護します。結果として、Web3プライバシーテクノロジーの利点と潜在的な適用シナリオは、2つの側面で反映されます:(1) 機密データのトレーニング、(2) データ連携:複数のデータ所有者が元のデータを共有せずにAIトレーニングに参加できます。
Web3における一般的なプライバシーテクノロジーには、Gate:が含まれています。
- 信頼された実行環境(TEE)、Super Protocolなど;
- 完全同型暗号(FHE)、BasedAI、Fhenix.io、またはInco Networkなどのようなもの;
- Zero-knowledge technology (zk), such as Reclaim Protocol using zkTLS technology, generates zero-knowledge proofs of HTTPS traffic, allowing users to securely import activity, reputation, and identity data from external websites without exposing sensitive information.
しかし、この分野はまだ初期段階にあり、ほとんどのプロジェクトがまだ探索段階にあります。現在、そのジレンマの1つは、計算コストがあまりにも高すぎることです。例として、いくつかの事例が挙げられます:
- zkMLフレームワークEZKLは1M-nanoGPTモデルの証明を生成するのに約80分かかります。
- Modulus Labsのデータによると、zkMLのオーバーヘッドは純粋な計算よりも1000倍以上高いです。
4. データストレージ:データを取得した後、チェーン上にデータを保存し、データから生成されたLLMを使用するための場所が必要です。データの可用性(DA)が中心の問題であり、イーサリアムのDankshardingアップグレード前のスループットは0.08MBでした。同時に、AIモデルのトレーニングとリアルタイム推論には通常、秒間50から100GBのデータスループットが必要です。この桁違いの差は、既存のオンチェーンソリューションが「リソース集約型のAIアプリケーション」に直面した際に不適切であることを示しています。
- 0g.AIは、このカテゴリーの代表的なプロジェクトです。これは、高性能AI要件向けに設計された集中型ストレージソリューションで、高性能とスケーラビリティを備え、高度なシャーディングやイレイジャーコーディング技術を用いた大規模データセットの高速アップロードとダウンロードをサポートし、データ転送速度は秒間5GBに近づいています。
2、ミドルウェア:モデルのトレーニングと推論
オープンソースモデルの分散型市場
AIモデルがオープンソースであるべきかクローズドソースであるべきかについての議論は決して止まることはありません。オープンソースによる集合的なイノベーションは、クローズドソースのモデルが追いつけない利点です。ただし、利益モデルがない前提のもとで、オープンソースのモデルが開発者のモチベーションをどのように向上させることができるのでしょうか?これは考える価値のある方向です。百度の創業者である李彦宏は、今年4月に「オープンソースのモデルはますます遅れをとるようになるだろう」と主張しました。
この点において、Web3は、分散型オープンソースモデル市場の可能性を提案しています。つまり、モデルそのものをトークン化し、一定割合のトークンをチームに割り当て、将来の収入の一部をトークン保有者に配分します。
- Bittensorプロトコルは、P2Pマーケットのオープンソースモデルを確立し、数十の「サブネット」で構成されています。ここでは、リソースプロバイダ(コンピューティング、データ収集/ストレージ、機械学習の専門家)が、特定のサブネット所有者の目標を達成するために競合します。サブネットは互いに対話し学習し合うことができ、より高度な知能を実現します。報酬はコミュニティの投票によって配布され、競争力のあるパフォーマンスに基づいてサブネット間でさらに割り当てられます。
- ORAは、分散型ネットワーク上での購入、販売、開発のためにAIモデルをトークン化するInitial Model Offering(IMO)のコンセプトを導入しています。
- Sentient, a decentralized AGI platform, incentivizes people to collaborate, build, replicate, and extend AI models, rewarding contributors.
- Spectral Novaは、AIおよびMLモデルの作成と適用に焦点を当てています。
検証可能な推論
AIの推論プロセスにおける「ブラックボックス」ジレンマに対する標準的なWeb3ソリューションは、複数の検証者が同じ操作を繰り返し、結果を比較することです。しかし、現在の高級「Nvidiaチップ」の不足により、このアプローチに直面する明白な課題は、AI推論の高コストです。
より有望な解決策は、オフチェーンのAI推論計算のZK証明を行うことで、1つの証明者が別の検証者に、与えられた文が真であることを証明できるようにすることです。その際、文が真であること以外の追加情報を公開しないようにし、許可なしでチェーン上でAIモデルの計算を検証できるようにします。これにより、オンチェーンで、オフチェーンの計算が正しく完了したこと(たとえば、データセットが改ざんされていないこと)を暗号化された形で証明する必要があります。すべてのデータが機密情報として残ることを確認しながら。
主な利点は次のとおりです:
- スケーラビリティ: ゼロ知識証明は、オフチェーン計算の大量の確認を迅速に行うことができます。取引の数が増えても、1つのゼロ知識証明ですべての取引を検証できます。
- プライバシー保護:データとAIモデルに関する詳細情報は機密に保たれていますが、すべての関係者がデータとモデルが改ざんされていないことを検証できます。
- 信頼する必要はありません:中央集権的な当事者に頼らずに計算を確認できます。
- Web2の統合:定義上、Web2はオフチェーンで統合されており、検証可能な推論が、そのデータセットやAIの計算をチェーン上にもたらすのを助けます。これにより、Web3の採用が向上します。
現在、Web3の検証可能な推論技術は以下の通りです:
- ZKML:ゼロ知識証明と機械学習を組み合わせて、データとモデルのプライバシーと機密性を確保し、特定の基本的な特性を明らかにせずに検証可能な計算を可能にします。 Modulus Labsは、AI構築のためのZKMLに基づくZKプルーバーをリリースし、AIプロバイダーが正しく実行されたアルゴリズムを操作しているかどうかを効果的に検証することができますが、現在、クライアントは主にオンチェーンDAppsです。
- opML:楽観的集約の原則を使用し、紛争発生時の時刻を検証することで、ML計算の拡張性と効率を向上させ、このモデルでは、'バリデータ'によって生成される結果の一部だけを検証する必要がありますが、バリデータによる不正行為のコストを高く設定して余分な計算を節約します。
- TeeML: 信頼できる実行環境を使用して、ML計算を安全に実行し、データとモデルを改ざんや不正アクセスから保護します。
Three, Application Layer: AI Agent
AIの現在の開発はすでにモデルの能力からAIエージェントの景観への焦点のシフトを示しています。OpenAI、AIのユニコーンであるAnthropic、Microsoftなどのテクノロジー企業は、LLMの現在の技術的な停滞を打破しようとして、AIエージェントの開発に取り組んでいます。
OpenAIは、AIエージェントを、その脳としてLLMによって駆動され、自律的に知覚を理解し、計画し、記憶し、ツールを使用し、複雑なタスクを自動的に完了できるシステムと定義しています。 AIが使用されるツールからツールを使用できる主体への移行すると、AIはAIエージェントになります。これが、AIエージェントが人間にとって最も理想的な知的アシスタントになり得る理由でもあります。
Web3はエージェントに何をもたらすことができるのか?
1. 分散化
Web3の分散化により、エージェントシステムはより分散化され、自律的になる可能性があります。ステーカーやデリゲート向けのインセンティブおよびペナルティメカニズムは、ガイアネット、セオリック、そしてハジメAIがそのような動きをしようとしているエージェントシステムの民主化を促進することができます。
2、Cold Start
AIエージェントの開発とイテレーションには、多額の資金支援が必要であり、Web3は有望なAIエージェントプロジェクトが早期の資金調達と冷たいスタートを得るのを支援することができます。
- Virtual Protocolは、AIエージェントの作成およびトークン発行プラットフォームfun.virtualsを立ち上げました。ここでは、誰でも1クリックでAIエージェントを展開し、AIエージェントトークンの100%公平な分配を実現できます。
- Spectralは、チェーン上でAIエージェント資産の発行をサポートする製品コンセプトを提案しています:IAO(Initial Agent Offering)を通じてトークンを発行し、AIエージェントは投資家から直接資金を調達できる一方、DAOガバナンスのメンバーになり、投資家にプロジェクト開発に参加し、将来の利益を共有する機会を提供します。
AIがWeb3をどのように強化するのか?
AIのWeb3プロジェクトへの影響は明らかであり、スマートコントラクトの実行、流動性最適化、AIによるガバナンスの意思決定などのオンチェーンオペレーションを最適化することでブロックチェーン技術に恩恵をもたらします。同時に、より良いデータ駆動型の洞察を提供し、オンチェーンセキュリティを向上させ、新しいWeb3ベースのアプリケーションの基盤を築くことも可能です。
One, AIとオンチェーンファイナンス
AIとCryptoeconomics
8月31日、CoinbaseのCEOであるBrian Armstrongは、Baseネットワーク上で初の暗号化されたAI間取引を発表し、AIエージェントが今やUSDを使用してBase上で人間、店舗、または他のAIと取引できると述べ、取引は即座でグローバルかつ無料であると述べました。
支払いに加えて、Virtuals ProtocolのLunaはAIエージェントが自律的にオンチェーン取引を実行する方法を初めて示し、環境を認識し、意思決定を行い、行動を起こすことができる知的エンティティとしてAIエージェントを位置付け、オンチェーンファイナンスの未来と見なされています。現在、AIエージェントの潜在的なシナリオは次のとおりです:
1. 情報収集と予測: 投資家が取引所の発表、プロジェクトの公開情報、パニック感情、世論リスクなどを収集し、資産の基礎、市況をリアルタイムで分析・評価し、トレンドやリスクを予測する手助けをします。
2. 資産管理:ユーザーに適した投資ターゲットを提供し、資産配分を最適化し、取引を自動的に実行します。
3. Financial experience: 投資家が最速のオンチェーン取引方法を選択し、クロスチェーン取引やガス手数料の調整などの手動操作を自動化し、オンチェーン金融活動の閾値とコストを削減するのを支援します。
このシナリオを想像してみてください:AIエージェントに次のように指示します。「1000USDTを持っています、1週間を超えるロックアップ期間で最も収益性の高い組み合わせを見つけるのを手伝ってください。」AIエージェントは次のアドバイスを提供します。「Aに50%、Bに20%、Xに20%、Yに10%の初期割り当てを提案します。金利を監視し、リスクレベルの変化を観察し、必要に応じてリバランスします。」さらに、ポテンシャルなエアドロッププロジェクトやMemecoinプロジェクトの人気コミュニティサインを探すことも、AIエージェントの可能な将来の行動です。

画像ソース:Biconomy
現在、AIエージェントウォレットBitteとAIインタラクションプロトコルWayfinderがそのような試みをしています。彼らはすべてOpenAIのモデルAPIにアクセスしようとしており、ユーザーがエージェントにさまざまなオンチェーン操作を完了させるように命令できるようにしています。これはChatGPTに似たチャットウィンドウインターフェースで行われます。たとえば、今年4月にWayFinderによってリリースされた最初のプロトタイプでは、Base、Polygon、Ethereumのメインネットでのスワップ、送信、ブリッジ、ステークの4つの基本操作が示されました。
現在、分散型エージェントプラットフォームMorpheusも、Biconomyによって示されたように、このようなエージェントの開発をサポートしており、ウォレットの許可がETHをUSDCにスワップするためにAIエージェントを認可する必要はありません。
AIとオンチェーン取引のセキュリティ
Web3の世界では、オンチェーン取引のセキュリティが重要です。AI技術を活用して、オンチェーン取引のセキュリティとプライバシー保護を強化することができ、潜在的なシナリオには以下が含まれます:
取引監視: リアルタイムデータ技術が異常な取引活動を監視し、ユーザーやプラットフォームにリアルタイムアラートインフラを提供します。
リスク分析:プラットフォームが顧客の取引行動データを分析し、リスクレベルを評価するのを支援します。
例えば、Web3セキュリティプラットフォームSeQureは、AIを使用して悪意のある攻撃、不正行為、データ漏洩を検出し、防止し、オンチェーン取引のセキュリティと安定性を確保するためのリアルタイムモニタリングとアラートメカニズムを提供しています。同様のセキュリティツールには、AI搭載のSentinelがあります。
AIとオンチェーンインフラストラクチャー
AIとオンチェーンデータ
AIテクノロジーは、オンチェーンのデータ収集と分析において、次のような重要な役割を果たします。
- Web3 Analytics: a AI-based analytics platform that uses machine learning and data mining algorithms to collect, process, and analyze on-chain data.
- MinMax AI: ユーザーが潜在的な市場機会やトレンドを発見するのを支援するためのAIベースのオンチェーンデータ分析ツールを提供します。
- Kaito: LLM検索エンジンに基づくWeb3検索プラットフォーム。
- 以下:ChatGPTと統合され、異なるウェブサイトやコミュニティプラットフォームに散在する関連情報を収集し統合して表示します。
- 別の適用シナリオは、オラクルであり、AIは複数のソースから価格を取得して正確な価格データを提供できます。 たとえば、UpshotはAIを使用してNFTの価格の変動を評価し、1時間あたり1億回以上の評価を通じて3〜10%の誤差を提供しています。
AIと開発&監査
最近、Web2 AIコードエディターであるCursorが開発者コミュニティで多くの注目を集めています。このプラットフォームでは、ユーザーは自然言語で説明するだけでよく、Cursorが自動的に対応するHTML、CSS、JavaScriptコードを生成することができます。これにより、ソフトウェア開発プロセスが大幅に簡素化されます。このロジックはWeb3開発の効率化にも適用されます。
現在、パブリックチェーン上でスマートコントラクトやDAppsを展開するには、通常、Solidity、Rust、Moveなどの専用開発言語に従う必要があります。新しい開発言語のビジョンは、分散型ブロックチェーンの設計空間を拡大し、DApp開発に適しているようにすることです。しかし、Web3開発者の大幅な不足を考慮すると、開発者教育は常により困難な問題となっています。
現在、Web3開発を支援するAIには、自動コード生成、スマートコントラクトの検証とテスト、DAppsの展開とメンテナンス、インテリジェントなコード補完、AIによる難しい開発課題への回答など、想像できるシナリオが含まれています。AIの支援により、開発効率と精度を向上させるだけでなく、プログラミングの敷居を下げ、非プログラマーが自分のアイデアを実用的なアプリケーションに変えるのを可能にし、分散型テクノロジーの開発に新たな活力をもたらします。
現在、最も注目されているのは、Clankerのような、急速なDIYトークン展開を目的としたAI駆動の「Token Bot」として設計された、ワンクリックでのトークンプラットフォームです。 WarpcastやSupercastのようなSocialFiプロトコルFarcasterクライアントにClankerをタグ付けし、トークンのアイデアを伝えるだけで、それが公開チェーンBase上でトークンを立ち上げます。
また、Spectralなどの契約開発プラットフォームもあり、これによりスマート契約のワンクリック生成や展開機能が提供され、Web3開発の敷居が下がり、初心者でもスマート契約をコンパイルして展開することができます。
監査に関して、Web3監査プラットフォームであるFuzzlandは、AIを使用して監査人がコードの脆弱性をチェックするのを支援し、自然言語の説明を提供して監査専門家を支援しています。Fuzzlandはまた、AIを使用して、形式仕様と契約コードの自然言語の説明を提供し、開発者がコード内の潜在的な問題を理解するのを支援するためのサンプルコードも提供しています。
Three, AIとWeb3新しいナラティブ
ジェネレーティブAIの台頭は、Web3の新しいナラティブに新たな可能性をもたらします。
NFT:AIはジェネレーティブNFTに創造性を注入します。AI技術により、ユニークで多様な様々な作品やキャラクターを生み出すことができます。これらのジェネレーティブNFTは、ゲーム、仮想世界、メタバース(BinanceのBicassoのように)のキャラクター、小道具、シーン要素になることができ、ユーザーは画像をアップロードしたり、AI計算のためのキーワードを入力したりすることでNFTを生成することができます。同様のプロジェクトには、Solvo、Nicho、IgmnAI、CharacterGPTなどがあります。
GameFi: 自然言語生成、画像生成、そしてAIを中心としたインテリジェントNPCの機能を備えたGameFiは、ゲームコンテンツの制作における効率と革新をもたらすことが期待されています。例えば、Binaryxの最初のチェーンゲームAI Heroでは、プレイヤーがAIのランダム性を通じて異なるプロットオプションを探索することができます。同様に、仮想コンパニオンゲームSleepless AIでは、AIGCとLLMに基づいた異なる相互作用を通じて、プレイヤーは個人のゲームプレイをアンロックすることができます。
DAO:現在、AIはDAOにも適用されることが想定されており、コミュニティの相互作用を追跡し、貢献を記録し、最も貢献度の高いメンバーに報酬を与えたり、代理投票などを支援することが期待されています。例えば、ai16zはAIエージェントを使用して、オンチェーンおよびオフチェーンで市場情報を収集し、コミュニティの合意を分析し、DAOメンバーからの提案と組み合わせて投資決定を行っています。
AI+Web3統合の意義:Tower and Square
イタリアのフィレンツェの中心には、地元の人々や観光客にとって最も重要な政治的な集会場所である中央広場があります。ここには高さ95メートルの市庁舎の塔があり、広場と劇的な美的効果を創出し、ハーバード大学の歴史教授であるニール・ファーガソンが世界のネットワークと階層の歴史を探求した『スクエアとタワー』という本の中で、時間の経過とともに両者の潮流を示しています。
この優れた比喩は、AIとWeb3の関係に適用するときには適切ではありません。長期的な、非線形の歴史的な関係を見ると、四角形は新しい創造的なものを生み出す可能性が高いが、塔にはそれでも正当性と強い生命力があることがわかる。
エネルギーコンピューティングパワーデータをクラスター化できる能力を持つテクノロジーカンパニーによって、AIは前代未聞の想像力を解放し、主要なテックジャイアントをリードし、異なるチャットボットからGPT-4、GP4-4oなどの '基盤となる大きなモデル' まで、さまざまなイテレーションを導入し、自動プログラミングロボット(Devin)や実際の物理世界をシミュレートする初期能力を持つSoraなどが次々と登場し、AIの想像力を無限に増幅させています。
同時に、AIは基本的に大規模で集中した産業であり、この技術革命は徐々に構造的な支配を得た技術企業を狭い高みに押し上げるでしょう。巨大な力、独占的なキャッシュフロー、そして知的時代を支配するために必要な膨大なデータセットは、それにより高い障壁を形成しています。
タワーが高くなり、舞台裏の意思決定者が小さくなるにつれて、AIの中央集権化は多くの隠れた危険をもたらします。広場に集まった大衆は、タワーの影の下をどうやって避けることができるのでしょうか?これはWeb3が解決しようとしている問題です。
基本的に、ブロックチェーンの固有の特性は人工知能システムを向上させ、主に新たな可能性をもたらします。
- 人工知能の時代において、「コードは法律である」—スマートコントラクトと暗号化検証を通じて透明なシステム自動実行ルールを実現し、ターゲットにより近い観客に報酬を提供する。
- トークン経済 - トークンメカニズム、ステーキング、削減、トークン報酬、およびペナルティを通じて参加者の行動を作成および調整します。
- 分散型ガバナンス-情報源を問い直し、人工知能技術に対するより批判的かつ洞察力のあるアプローチを促し、偏見、誤情報、操作を防ぎ、結果としてより情報が豊富で力を持った社会を育むよう奨励します。
AIの発展はWeb3にも新しい活力をもたらしており、おそらくWeb3のAIへの影響は証明する時間が必要ですが、AIのWeb3への影響は直ちに現れています。それはMemeの熱狂であろうと、AIエージェントがオンチェーンアプリケーションの参入障壁を下げるのを手伝うであろうと、すべてが明白です。
Web3が一部の人々によって自己満足と定義され、伝統的な産業の模倣に疑念を抱かれている中、AIの導入により予見可能な未来がもたらされます:より安定してスケーラブルなWeb2ユーザーベース、より革新的なビジネスモデルやサービス。
私たちは、AIとWeb3が異なるタイムラインと出発点を持ちながらも、「タワーと広場」が共存する世界に生きています。彼らの究極の目標は、どのようにして機械が人類により良く仕えるかを実現することであり、誰も急ぐ川を定義することはできません。私たちはAI+Web3の未来を楽しみにしています。
ステートメント:
- この記事は[から転載されましたテックフロー,著作権は元の著者に属します[Coinspire],如对转载有异议,请联系 Gate Learn Team、チームは関連手続きに従ってできるだけ早く処理します。
- 免責事項:この記事で表現されている意見は、著者個人のものであり、投資アドバイスを構成するものではありません。
- その記事は、Gate Learnチームによって他の言語に翻訳されます。もし言及されていない場合Gate.io翻訳された記事をコピー、配布、または盗用してはなりません。
関連記事


ブロックチェーンについて知っておくべきことすべて

ステーブルコインとは何ですか?

流動性ファーミングとは何ですか?

Cotiとは? COTIについて知っておくべきことすべて
