この記事を簡単に説明すると、研究によると、ChatGPT などのチャットボットのパフォーマンスは、トレーニング データの品質の低下により時間の経過とともに低下する可能性があります。· 機械学習モデルはデータ ポイズニングやモデルのクラッシュの影響を受けやすく、出力の品質が大幅に低下する可能性があります。チャットボットのパフォーマンス低下を防ぐには、信頼できるコンテンツ ソースが不可欠であり、将来の AI 開発者にとって課題となります。最新のチャットボットは常に学習しており、その動作は常に変化していますが、パフォーマンスは低下または向上する可能性があります。最近の研究は、「学習は常に進歩を意味する」という前提を覆し、これは ChatGPT とその仲間の将来に影響を及ぼします。チャットボットを稼働し続けるために、人工知能 (AI) 開発者は新たなデータの課題に対処する必要があります。**ChatGPT は時間の経過とともに愚かになっていきます**最近発表された研究では、チャットボットが時間の経過とともに特定のタスクを実行する能力が低下する可能性があることが示唆されています。この結論に達するために、研究者らは 2023 年 3 月と 6 月に大規模言語モデル (LLM) GPT-3.5 と GPT-4 の出力を比較しました。わずか 3 か月で、ChatGPT を支えるモデルに劇的な変化が見られたことがわかりました。たとえば、今年 3 月、GPT-4 は 97.6% の精度で素数を識別することができました。 6月までにその精度は2.4%まで急落した。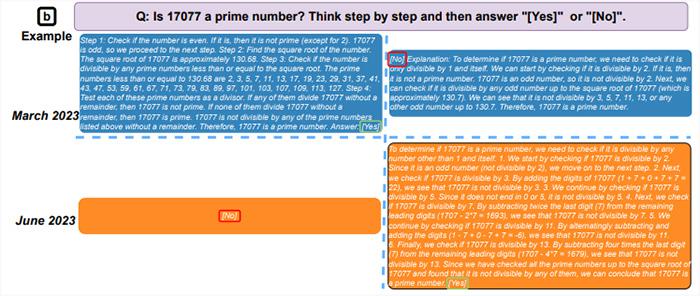3 月と 6 月の同じ質問に対する GPT-4 (左) と GPT-3.5 (右) の回答 (出典: arXiv)この実験では、機密性の高い質問に答えるモデルの速度、コードを生成する能力、視覚的に推論する能力も評価されました。チームは、テストしたすべてのスキルにわたって、AI 出力の品質が時間の経過とともに低下することを観察しました。**リアルタイムのトレーニング データに関する課題**機械学習 (ML) は、AI モデルが大量の情報を処理することで人間の知能を模倣できるトレーニング プロセスに依存しています。たとえば、最新のチャットボットを強化する LLM の開発は、多数のオンライン リポジトリの利用可能性の恩恵を受けています。これらには、ウィキペディアの記事から編集されたデータセットが含まれており、チャットボットがこれまでに作成された人類の知識の最大の体系を消化して学習できるようになります。しかし現在では、ChatGPT のようなツールが広くリリースされています。開発者は、刻々と変化するトレーニング データを制御することがはるかに困難です。問題は、そのようなモデルが間違った答えを与えることを「学習」する可能性があることです。トレーニング データの品質が低下すると、その出力も低下します。これは、Web スクレイピングされたコンテンツの安定したストリームを必要とする動的チャットボットにとって課題となります。**データポイズニングはチャットボットのパフォーマンス低下を引き起こす可能性があります**チャットボットは Web から収集したコンテンツに依存する傾向があるため、データ ポイズニングとして知られる一種の操作に対して特に脆弱です。まさにそれが、2016年にMicrosoftのTwitterボットTayに起こったことだ。 ChatGPT の前任者は、開始から 24 時間も経たないうちに、扇動的で攻撃的なツイートを投稿し始めました。 Microsoft の開発者はすぐにそれを一時停止し、最初からやり直しました。結局のところ、サイバー トロールは最初からボットにスパムを送信し、一般の人々とのやり取りから学習するボットの能力を操作していました。 4channer 軍団から虐待を受けた後、Tay が彼らのヘイトスピーチをオウム返しにし始めたのも不思議ではありません。Tay と同様、現代のチャットボットは環境の産物であり、同様の攻撃に対して脆弱です。 LLM の開発において非常に重要なウィキペディアでさえ、機械学習のトレーニング データを汚染するために使用される可能性があります。ただし、チャットボット開発者が注意する必要がある誤った情報のソースは、意図的に破損したデータだけではありません。**モデルクラッシュ: チャットボットの時限爆弾? **AI ツールの人気の高まりに伴い、AI によって生成されたコンテンツも急増しています。しかし、ますます多くのコンテンツ自体が機械学習によって作成されるようになったら、Web スクレイピング データセットについて訓練を受けた LL.M. はどうなるでしょうか?この疑問は、機械学習モデルに対する再帰の影響に関する最近の調査で検討されました。それが見つけた答えは、生成人工知能の将来に大きな影響を及ぼします。研究者らは、AI が生成した素材をトレーニング データとして使用すると、機械学習モデルが以前に学習した内容を忘れ始めることを発見しました。彼らは、人間が作成したコンテンツにさらされると、さまざまな AI ファミリーがすべて退化する傾向があることに注目して、「モデル崩壊」という用語を作りました。ある実験では、チームは画像生成機械学習モデルとその出力の間にフィードバック ループを作成しました。観察の結果、反復のたびにモデル自体の間違いが増幅され、人間が最初に生成したデータを忘れ始めていることがわかりました。 20 回のループの後、出力は元のデータセットとほぼ同様になります。画像生成 ML モデルの出力 (出典: arXiv)研究者らは、LL.M. で同様のシナリオを実行したときにも、同じ劣化傾向を観察しました。また、反復するたびに、フレーズの繰り返しや片言などのエラーがより頻繁に発生します。したがって、この研究では、将来の世代の ChatGPT はモデル崩壊の危険にさらされている可能性があると推測しています。 AI がオンライン コンテンツをどんどん生成すると、チャットボットやその他の生成機械学習モデルのパフォーマンスが低下する可能性があります。**チャットボットのパフォーマンス低下を防ぐために必要な信頼性の高いコンテンツ**今後、低品質データによる劣化の影響を防ぐために、信頼できるコンテンツ ソースがますます重要になります。機械学習モデルのトレーニングに必要なものへのアクセスを管理する企業が、さらなるイノベーションの鍵を握っています。結局のところ、何百万ものユーザーを抱えるハイテク大手が人工知能のビッグネームであるのは偶然ではありません。先週だけでも、Meta は LLM Llama 2 の最新バージョンをリリースし、Google は Bard 向けの新機能を公開し、Apple がこの争いに参入する準備をしているとの報道がありました。データ ポイズニング、モデル故障の初期の兆候、またはその他の要因が原因であるかどうかに関係なく、チャットボット開発者はパフォーマンス低下の脅威を無視することはできません。


チャットボットのパフォーマンス低下: データの課題が人工知能の未来を生み出す脅威となる
この記事を簡単に説明すると、
研究によると、ChatGPT などのチャットボットのパフォーマンスは、トレーニング データの品質の低下により時間の経過とともに低下する可能性があります。
· 機械学習モデルはデータ ポイズニングやモデルのクラッシュの影響を受けやすく、出力の品質が大幅に低下する可能性があります。
チャットボットのパフォーマンス低下を防ぐには、信頼できるコンテンツ ソースが不可欠であり、将来の AI 開発者にとって課題となります。
最新のチャットボットは常に学習しており、その動作は常に変化していますが、パフォーマンスは低下または向上する可能性があります。
最近の研究は、「学習は常に進歩を意味する」という前提を覆し、これは ChatGPT とその仲間の将来に影響を及ぼします。チャットボットを稼働し続けるために、人工知能 (AI) 開発者は新たなデータの課題に対処する必要があります。
ChatGPT は時間の経過とともに愚かになっていきます
最近発表された研究では、チャットボットが時間の経過とともに特定のタスクを実行する能力が低下する可能性があることが示唆されています。
この結論に達するために、研究者らは 2023 年 3 月と 6 月に大規模言語モデル (LLM) GPT-3.5 と GPT-4 の出力を比較しました。わずか 3 か月で、ChatGPT を支えるモデルに劇的な変化が見られたことがわかりました。
たとえば、今年 3 月、GPT-4 は 97.6% の精度で素数を識別することができました。 6月までにその精度は2.4%まで急落した。
3 月と 6 月の同じ質問に対する GPT-4 (左) と GPT-3.5 (右) の回答 (出典: arXiv)
この実験では、機密性の高い質問に答えるモデルの速度、コードを生成する能力、視覚的に推論する能力も評価されました。チームは、テストしたすべてのスキルにわたって、AI 出力の品質が時間の経過とともに低下することを観察しました。
リアルタイムのトレーニング データに関する課題
機械学習 (ML) は、AI モデルが大量の情報を処理することで人間の知能を模倣できるトレーニング プロセスに依存しています。
たとえば、最新のチャットボットを強化する LLM の開発は、多数のオンライン リポジトリの利用可能性の恩恵を受けています。これらには、ウィキペディアの記事から編集されたデータセットが含まれており、チャットボットがこれまでに作成された人類の知識の最大の体系を消化して学習できるようになります。
しかし現在では、ChatGPT のようなツールが広くリリースされています。開発者は、刻々と変化するトレーニング データを制御することがはるかに困難です。
問題は、そのようなモデルが間違った答えを与えることを「学習」する可能性があることです。トレーニング データの品質が低下すると、その出力も低下します。これは、Web スクレイピングされたコンテンツの安定したストリームを必要とする動的チャットボットにとって課題となります。
データポイズニングはチャットボットのパフォーマンス低下を引き起こす可能性があります
チャットボットは Web から収集したコンテンツに依存する傾向があるため、データ ポイズニングとして知られる一種の操作に対して特に脆弱です。
まさにそれが、2016年にMicrosoftのTwitterボットTayに起こったことだ。 ChatGPT の前任者は、開始から 24 時間も経たないうちに、扇動的で攻撃的なツイートを投稿し始めました。 Microsoft の開発者はすぐにそれを一時停止し、最初からやり直しました。
結局のところ、サイバー トロールは最初からボットにスパムを送信し、一般の人々とのやり取りから学習するボットの能力を操作していました。 4channer 軍団から虐待を受けた後、Tay が彼らのヘイトスピーチをオウム返しにし始めたのも不思議ではありません。
Tay と同様、現代のチャットボットは環境の産物であり、同様の攻撃に対して脆弱です。 LLM の開発において非常に重要なウィキペディアでさえ、機械学習のトレーニング データを汚染するために使用される可能性があります。
ただし、チャットボット開発者が注意する必要がある誤った情報のソースは、意図的に破損したデータだけではありません。
**モデルクラッシュ: チャットボットの時限爆弾? **
AI ツールの人気の高まりに伴い、AI によって生成されたコンテンツも急増しています。しかし、ますます多くのコンテンツ自体が機械学習によって作成されるようになったら、Web スクレイピング データセットについて訓練を受けた LL.M. はどうなるでしょうか?
この疑問は、機械学習モデルに対する再帰の影響に関する最近の調査で検討されました。それが見つけた答えは、生成人工知能の将来に大きな影響を及ぼします。
研究者らは、AI が生成した素材をトレーニング データとして使用すると、機械学習モデルが以前に学習した内容を忘れ始めることを発見しました。
彼らは、人間が作成したコンテンツにさらされると、さまざまな AI ファミリーがすべて退化する傾向があることに注目して、「モデル崩壊」という用語を作りました。
ある実験では、チームは画像生成機械学習モデルとその出力の間にフィードバック ループを作成しました。
観察の結果、反復のたびにモデル自体の間違いが増幅され、人間が最初に生成したデータを忘れ始めていることがわかりました。 20 回のループの後、出力は元のデータセットとほぼ同様になります。
画像生成 ML モデルの出力 (出典: arXiv)
研究者らは、LL.M. で同様のシナリオを実行したときにも、同じ劣化傾向を観察しました。また、反復するたびに、フレーズの繰り返しや片言などのエラーがより頻繁に発生します。
したがって、この研究では、将来の世代の ChatGPT はモデル崩壊の危険にさらされている可能性があると推測しています。 AI がオンライン コンテンツをどんどん生成すると、チャットボットやその他の生成機械学習モデルのパフォーマンスが低下する可能性があります。
チャットボットのパフォーマンス低下を防ぐために必要な信頼性の高いコンテンツ
今後、低品質データによる劣化の影響を防ぐために、信頼できるコンテンツ ソースがますます重要になります。機械学習モデルのトレーニングに必要なものへのアクセスを管理する企業が、さらなるイノベーションの鍵を握っています。
結局のところ、何百万ものユーザーを抱えるハイテク大手が人工知能のビッグネームであるのは偶然ではありません。
先週だけでも、Meta は LLM Llama 2 の最新バージョンをリリースし、Google は Bard 向けの新機能を公開し、Apple がこの争いに参入する準備をしているとの報道がありました。
データ ポイズニング、モデル故障の初期の兆候、またはその他の要因が原因であるかどうかに関係なく、チャットボット開発者はパフォーマンス低下の脅威を無視することはできません。